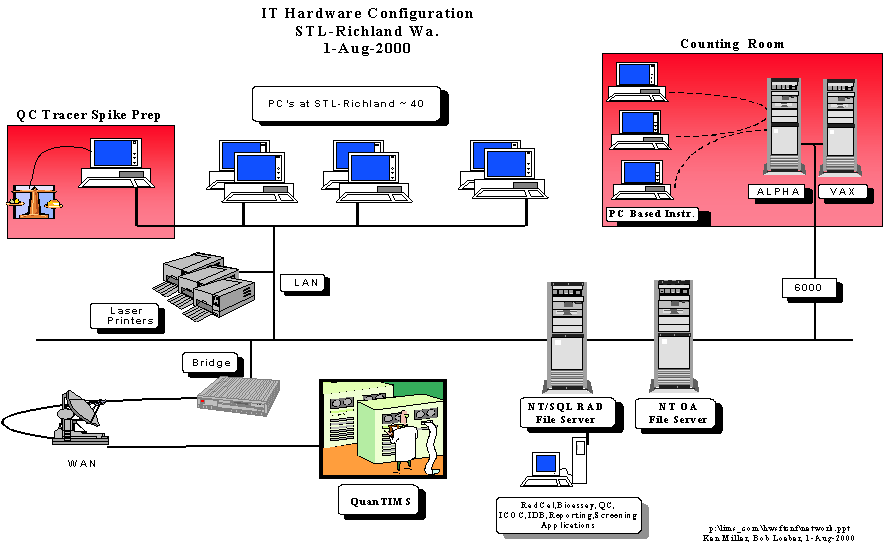
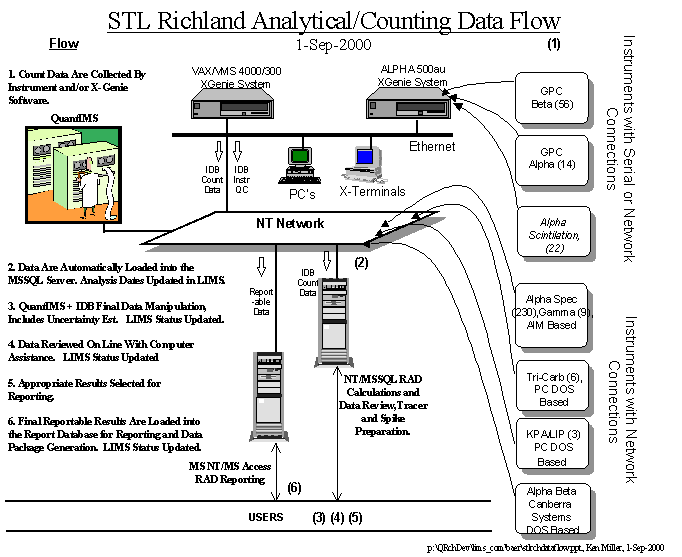
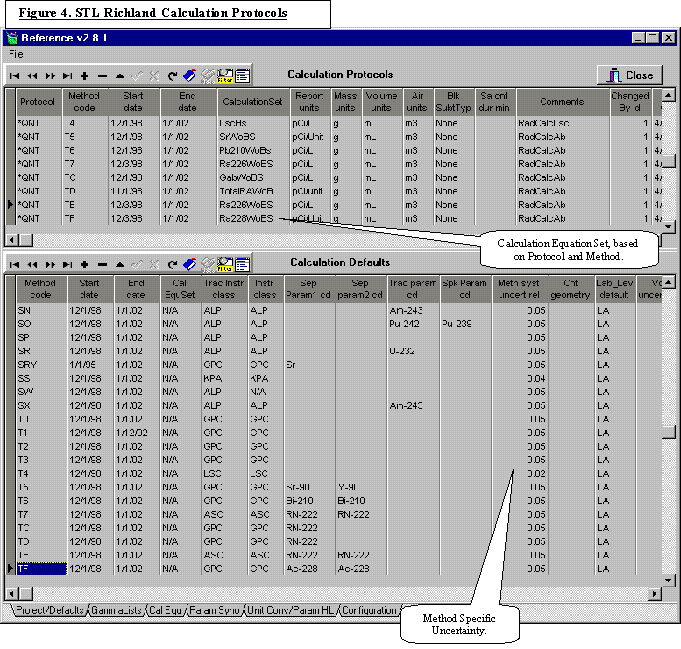
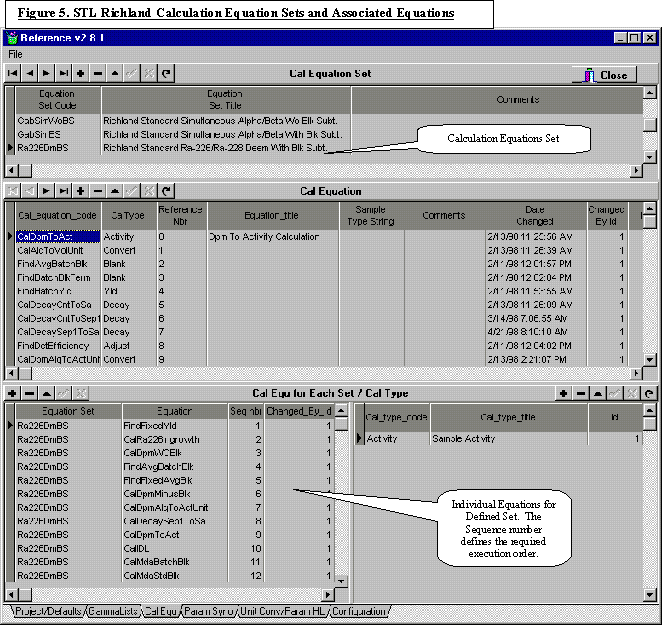
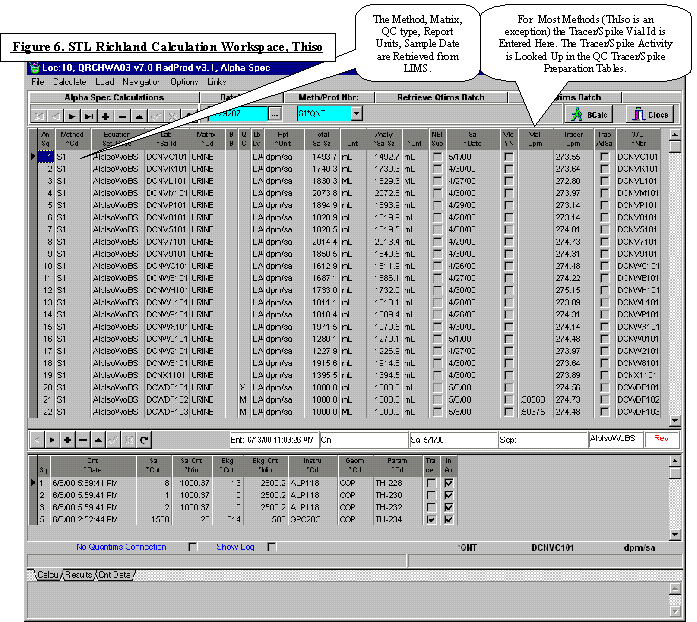
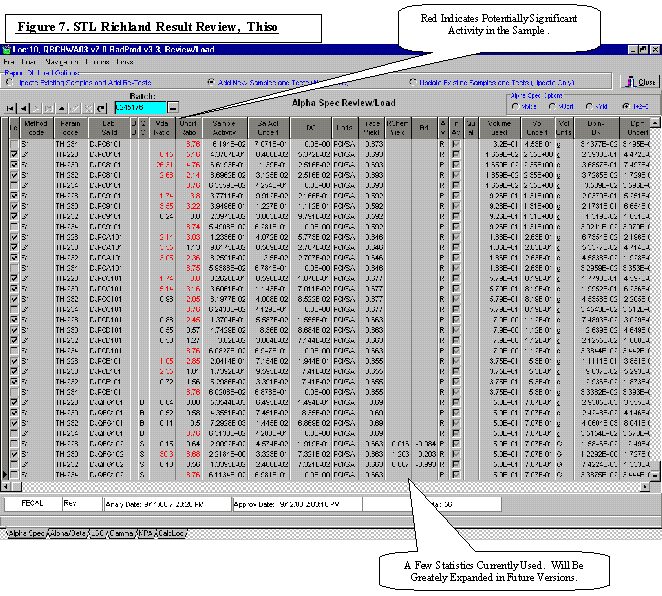
Laboratory Data and Information Technology
Kenneth V Miller, STL Richland, v1.7
Introduction
This topic developed from observing the failure of four Laboratory Information Management Systems (LIMS) development projects by four difference corporations. In brief, the software development failures were due to the complexity of the product, the overwhelming effort required, and the instability in the analytical laboratory market place. Laboratories are not in the business to write software, but in today’s environment it is impossible to stay in business without automated systems. The instrument and LIMS software vendors only provide partial solutions. The complete solution is for the laboratories to take control, understand what it is they are trying to do, and commit sustainable resources to software enhancements.
Classification of Laboratory Data
The classification of laboratory data provides insight into the type of software needed, the experts who understand the underlying concept of the data, and the attributes of the software needed to manage the data. Table I illustrates the classification of laboratory data and the attributes critical to the software development.
Table I. Classification of Laboratory Data |
Attributes |
||||
|
Classification Scale: 0 None, 1 Low to 5 High |
Specificity to
Laboratory Business |
Data Manipulation /Interpretation |
Laboratory
Dependencies |
Experts Who
Uunderstand Concepts |
|
|
Management |
Client/Project Specifications |
1-Low |
0-None |
1 |
Lab |
|
|
Reporting Requirements |
1 |
0 |
1 |
Lab |
|
|
Validation Requirements |
1 |
0 |
1 |
Lab |
|
|
Sample Status Information |
1 |
1 |
1 |
Corp./Lab |
|
|
Scheduling Information |
1 |
2 |
2 |
Corp./Lab |
|
|
Invoicing Information |
1 |
2 |
1 |
Corp./Lab |
|
|
|
|
|
|
|
|
Reportable Data |
Final Results |
1 |
1 |
1 |
Work Group |
|
|
Batch/Method QC |
5 |
4 |
4 |
Work Group |
|
|
Client Supplied Data |
1 |
1 |
1 |
Lab |
|
|
Performance indicators |
3 |
3 |
3 |
Lab |
|
|
QC Limits |
3 |
3 |
3 |
Lab |
|
|
Selected Instrument Data |
5 |
3 |
4 |
Work Group |
|
|
|
|
|
|
|
|
Validation Data |
Batch/Method QC |
5 |
4 |
4 |
Work Group |
|
|
Instrument QC |
5 |
4 |
4 |
Work Group |
|
|
QC Limits |
|
|
|
Lab |
|
|
|
|
|
|
|
|
Instrument Data |
Channel Data |
5-High |
5 |
5 |
Work Group |
|
|
Integrated Data |
5 |
5 |
5 |
Work Group |
|
|
Calibration Data |
5 |
5 |
5 |
Work Group |
|
|
Check/Background Data |
5 |
5 |
5 |
Work Group |
|
|
|
|
|
|
|
|
Raw Data Calculations |
Final Results and Uncertainty |
5 |
5 |
5 |
A few Individuals |
|
|
|
|
|
|
|
|
Specificity to Laboratory
Business –
Is the data specific to the laboratory business or do the concepts apply to
other businesses. Data
Manipulation/Interpretation – Is the data derived or a significant degree of
interpretation required or just an attribute of some object.
Laboratory Dependencies – Is the data likely to be
dependent on a particular lab or is it similar in all RAD labs. Experts who
understand the concepts – The domain experts, those who understand the
underlying concepts of deriving, evaluating, and/or analyzing the data.
Work
Group – A small group of laboratory associates having common tasks, often
they are in the same department. |
|||||
Table I suggests that the management data should lend itself to relatively “simple” generic software development even by developers not familiar with the laboratory business. As we move down the table, there are fewer problem domain experts, and there is a high degree of laboratory dependence on how the data are derived and interpreted that make generic software development much more challenging. With the expansive scope of a LIMS, the software task is simplified by considering the most important attributes of a LIMS that help run the laboratory.
Critical LIMS Attributes
The LIMS is involved in
most day to day activities to the point where the LIMS becomes the business
model. The LIMS will dictate how the
business functions. It is critical the
LIMS possess three attributes to be successful in the laboratory.
1.
Centralized Data
ü
The data must be
accessible where it is needed.
ü
The centralization can
be conceptual (logical). That is, the
centralization does not have to be physical.
ü
The data should
include instrument data needed for evaluation and reporting.
2.
Usability
ü
The software must be
somewhat intuitive.
ü
Determined to a large
part by the user interface, i.e., screen presentations and reports.
ü
Adopting a MS Windows
“standard” interface goes a long way to making the software intuitive.
3.
Extensibility
ü
The LIMS must
accommodate extensions.
ü
Must allow for the
addition of object attributes.
ü
The laboratory must be
able to add middle-ware that works with the LIMS.
There are many more attributes that could be listed but these are the fundamental attributes that should be the starting point for any useful LIMS. The approach to software development in the laboratory must be carefully considered.
Development Models
Commercial LIMS – If
the business model can accommodate the changes needed to use a commercial LIMS
then this is a good option. For many
laboratories, this option may be sufficient.
Customized Commercial LIMS – A
commercial LIMS with a limited amount of customization to accommodate the
laboratory business model and/or to extend the functionality is often the best
solution. This assumes that the vendor
starts with an established product and makes some modification that the vendor
supports.
Corporate Developed LIMS – With
enough resources and time this approach can take a laboratory’s business model
and make it the basis for the LIMS.
Experience suggests that corporate written LIMS that try to do
everything:
ü
Are
often incomplete.
ü
Have
a good chance they will never be fully implemented.
ü
Often
fail to meet the needs in one or more areas within the laboratory.
ü
Frequently
cause the fragmentation of software and data to occur spontaneously and
immediately as a result of the previous three items.
These limitations are not due to the designer’s failure to understand the requirements or their technical abilities, but due to the difficulties and resources needed to transform the requirements into a useable product. A corporate LIMS should concentrate on selected areas and not try to do everything for the laboratory.
Heterogeneous (Hybrid) LIMS – In
many cases a hybrid LIMS can accommodate the laboratory needs. This involves fusing together a commercial
or corporate LIMS with laboratory written software components. The laboratory written software will be
referred to as middle-ware. Table I
suggests the following segregation of efforts.
1.
Corporate
(Central) Team or Commercial LIMS can adequately handle the management data and
related information including, Client, Projects, Test/Method Definition,
Batching, Revenue, and Invoicing.
2.
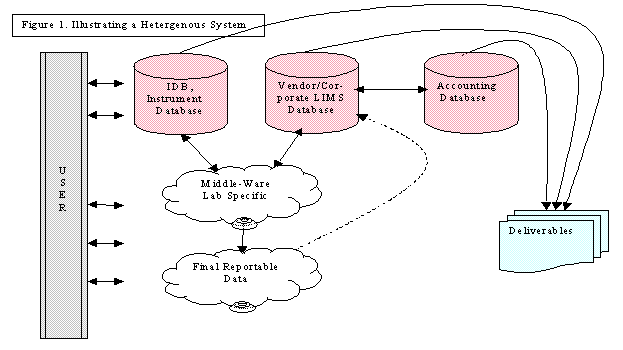
Laboratory Supported
software should concentrate on what the laboratory knows best, the laboratory
generated data. This includes
laboratory instrument data (the software is often supplied by another vendor),
data manipulation software, EDDs, and anything else related to generating
laboratory data.
Recommended Approach, Ignoring any Constraints
1.
Purchase
a Commercial LIMS with the following attributes:
ü
Based
on a major database (Oracle, Microsoft SQL Server Database (MSSQL) v7.0+).
ü
Written
in an established programming language.
ü
Conceptually
similar to the laboratory business model.
ü
Can
be modified and “easily” extended.
ü
Has
PC Connectivity.
2.
Implement
the LIMS with vendor support that includes some customization.
3.
After
6 to 12 months start modifying/extending the LIMS to meet the laboratory’s
exact needs, which may include:
ü
Instrument
Database (IDB) that may require some LIMS vendor support.
ü
Data
validation package.
ü
Table
Driven EDD generator.
ü
Integrate
all components.
It is critical for the laboratory to have a local expert who has some involvement in writing software. If the users don’t have a local expert to help figure out how best to use the system, they will often use inefficient paths to solve a particular problem. This can lead to user written spreadsheets and software that will fragment the LIMS. That is, islands of data and software will exist within the laboratory.