All of the terms in Equation 6 are evaluated in terms of known quantities, or
in terms of the unknown ![]() , except for the flux term. To effect closure,
the flux vector across each face of the cell,
, except for the flux term. To effect closure,
the flux vector across each face of the cell,
![]() , must be
expressed in terms of
, must be
expressed in terms of
![]() .
.
Evaluating the flux equation, Equation 3, at a particular face gives
![]()
The flux source,
![]() , is known. The diffusion coefficient, Dc, f,
is known within a cell, but may be discontinuous at the cell face. In general,
one cannot evaluate a gradient by taking differences across a material
interface because the gradient is discontinuous along the interface. It is
often assumed that one can take differences across a material discontinuity
if one uses a proper average of the two diffusion coefficients on each side
of the discontinuity. However, it will be shown that this is possible only on
orthogonal meshes. To avoid taking differences across material discontinuities,
an intensity unknown is added to each cell face. The interface flux is then
evaluated using two independent differences, with each difference being
constructed solely from unknowns from a single cell. An equation for each
interface intensity is obtained by requiring these independent differences
to yield the same flux.
, is known. The diffusion coefficient, Dc, f,
is known within a cell, but may be discontinuous at the cell face. In general,
one cannot evaluate a gradient by taking differences across a material
interface because the gradient is discontinuous along the interface. It is
often assumed that one can take differences across a material discontinuity
if one uses a proper average of the two diffusion coefficients on each side
of the discontinuity. However, it will be shown that this is possible only on
orthogonal meshes. To avoid taking differences across material discontinuities,
an intensity unknown is added to each cell face. The interface flux is then
evaluated using two independent differences, with each difference being
constructed solely from unknowns from a single cell. An equation for each
interface intensity is obtained by requiring these independent differences
to yield the same flux.
Actual expressions for the gradient in non-orthogonal coordinate systems
will now be considered. The values of ![]() at four non-planar points
are necessary and sufficient to determine the gradient. Since the mesh
is unstructured, a unique coordinate system will be defined for each
cell. Any four non-planar points (
at four non-planar points
are necessary and sufficient to determine the gradient. Since the mesh
is unstructured, a unique coordinate system will be defined for each
cell. Any four non-planar points (
![]() ,
,![]() ,
,![]() ,
,![]() ) define a local coordinate system
(see Figure 3) in
) define a local coordinate system
(see Figure 3) in

![\begin{displaymath}\left[ \begin{array}{c}
P^x \ [1em]
P^y \ [1em]
P^z
\e...
...m]
{\cal P}^l \ [1em]
{\cal P}^m
\end{array} \right] \; .
\end{displaymath}](img33.gif)
Note that an equally valid inverse transformation from the
![]() x, y, z
x, y, z![]() coordinate system to the
coordinate system to the
![]() k, l, m
k, l, m![]() coordinate system could have been
used, with a Jacobian matrix equal to
J-1. However, since
the four points are located along the axes in (k, l, m)-space, but not in
(x, y, z)-space, it is easier to take the derivatives needed for the forward
Jacobian than the reverse Jacobian:
coordinate system could have been
used, with a Jacobian matrix equal to
J-1. However, since
the four points are located along the axes in (k, l, m)-space, but not in
(x, y, z)-space, it is easier to take the derivatives needed for the forward
Jacobian than the reverse Jacobian:
![\begin{eqnarray}\html{eqn22}
\mathbf{J}
& \! \! = \! & \left[ \begin{array}{ccc...
...}{ccc}
\hat{k} & \hat{l} & \hat{m} \\
\end{array} \right] \; .
\end{eqnarray}](img35.gif)
Returning to the consideration of the gradient term and expanding the k,
l and m derivatives of ![]() using the chain rule yields
using the chain rule yields
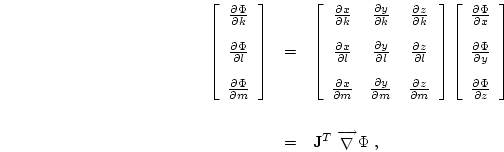
![\begin{displaymath}\mbox{$\mbox{$\stackrel{^{\mathstrut}\smash{\longrightarrow}}...
...\Phi_1 \ [1em]
\Phi_4 - \Phi_1 \\
\end{array} \right] \; .
\end{displaymath}](img38.gif)
This method of representing gradients is exact for linear functions, but only approximate for higher order functions.
Four points are not the only way to determine a gradient, for instance,
six points that form three lines intersecting in a single point can also be
used. A six points gradient is actually used to determine the fluxes on the
faces of the cell. If a point (and therefore an unknown ![]() ) is placed
in the center of each face, the three lines formed by connecting opposing
faces all intersect at the cell center. A single Jacobian matrix per cell
is then sufficient to determine the necessary gradients.
) is placed
in the center of each face, the three lines formed by connecting opposing
faces all intersect at the cell center. A single Jacobian matrix per cell
is then sufficient to determine the necessary gradients.
If the vectors connecting the face centers of opposite faces are denoted
![]() ,
,
![]() , and
, and
![]() for the k, l, and m directions
(see Figure 4), then the Jacobian matrix is given by
for the k, l, and m directions
(see Figure 4), then the Jacobian matrix is given by
The values for the k, l and m derivatives of ![]() have yet to be
defined. These are defined in terms of the seven unknown
have yet to be
defined. These are defined in terms of the seven unknown ![]() 's in each
cell. If the origin is placed at the center of the cell, then the locations
of the unknown
's in each
cell. If the origin is placed at the center of the cell, then the locations
of the unknown ![]() 's in (k, l, m)-space are
's in (k, l, m)-space are
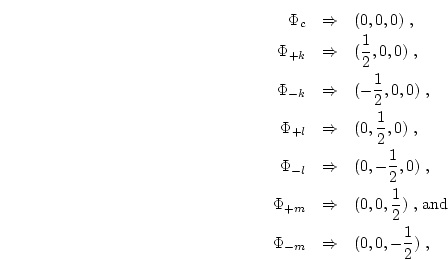
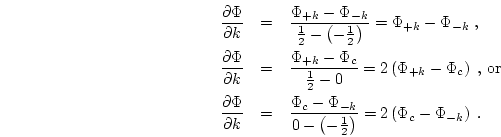
The gradient must be determined for each face of the cell. Each face must have definitions for all of the k, l and m derivatives. For a given face, the direction which is perpendicular to the face is called the major direction, because it is the only direction for which the derivative is non-zero if the cell is orthogonal, and it is usually the main contributor to the flux across the face. The other directions are called the minor directions for that face.
To compute the gradient for a face, full-cell derivatives are used for the
minor directions. The half-cell derivative which involves the face in question
is used for the major direction. For example, for the + k face the major
direction is the k direction, and the minor directions are the l and
m directions.
The gradient for the + k face is represented by the cell value for the
J-T matrix multiplied by the k, l and m derivative
vector for that face:
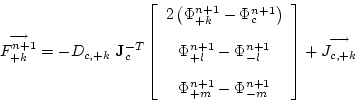
Figure 5 shows the stencil for each face gradient that is given by
this method.
![\includegraphics[angle=-90,scale=.5]{/home/hall/Caesar/documents/images/Augustus/4points.ps}](img22.gif)
![\includegraphics[angle=-90,scale=.7]{/home/hall/Caesar/documents/images/Augustus/jacob.ps}](img42.gif)
![\begin{eqnarray}\html{eqn39}
\lefteqn{\mathbf{J}^{-T} =}
\\
& & \hspace{-3ex...
...htarrow}}{J_l}$} \right) \\
\end{array} \right] \nonumber \; .
\end{eqnarray}](img44.gif)
![\includegraphics[angle=-90,scale=.7]{/home/hall/Caesar/documents/images/Augustus/stencil.ps}](img48.gif)